We are happy to announce that we have received six months of support from the Prototype Fund, a project of the Open Knowledge Foundation Germany and the Federal Ministry of Education and Research, to improve the way human rights organisations analyse document collections by combining human expert knowledge with machine intelligence.
Currently, we are able to use machine learning for individual Uwazi projects, like our work with ICAAD in which we apply machine learning to detect judicial bias in the Pacific Islands. But we have a much more ambitious vision of incorporating this technology into Uwazi to be used by any human rights organisation. In this blog post we sketch our vision for Uwazi and show-case how organisations can benefit from machine learning.
Uwazi, which means “openness” in Swahili, was developed to make human rights information more accessible and transparent to the defenders who rely on it. Uwazi is a web-based platform that goes beyond just storing and tagging documents. Human rights organisations are using Uwazi to add layers of context to raw documents, such as written reports, court documents, interviews, or video transcripts, in order to make these collections more understandable. With the integration of machine learning we want to further exploit Uwazi’s potential.
Applying machine learning features to Uwazi
Machine learning can reduce the tedious manual extraction of information, offer new ways to explore documents by identifying patterns that are impossible to detect for a human reader, and automate tasks by learning from examples. Integrating these features into Uwazi will make this transformative technology accessible to human rights organisations.
The following sections outline the different features we have in mind and how they can be used to better understand and share the stories within human rights document collections:
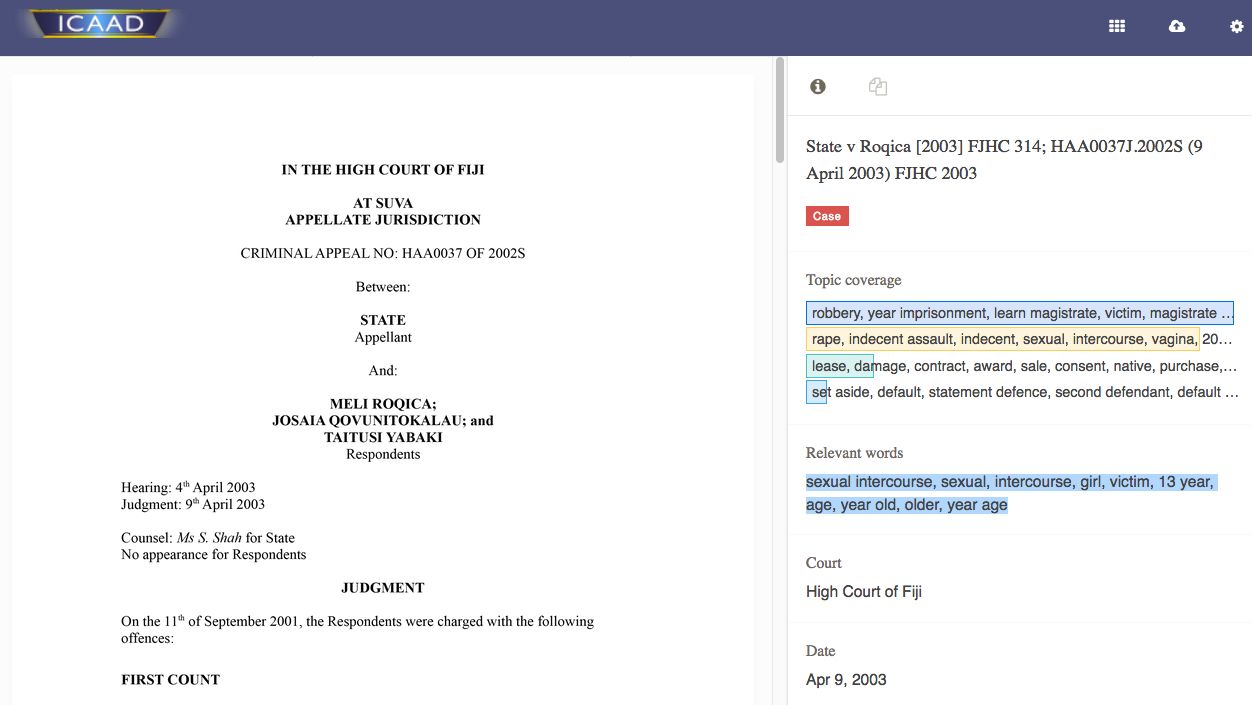
Automated extraction of person names, countries, organisations and dates
Often actors, locations and dates provide key information necessary to organise and connect documents. Ready-made algorithms exist but are not accessible to most human rights organisations because of the coding knowledge it requires, or the purchase of separate software.
Integrating automated feature extraction into Uwazi does not only solve this problem, but also offers the possibility to filter the document collection based on this information. Imagine a large collection of case law documents from all over Africa. Extracting the country and involved persons from each of these documents would allow a lawyer to filter the documents based on her region of interest and even identify which ones are related to her client. With automated extraction, this data can be captured without manually combing through the documents, extracting the country, or manually searching for the client’s name.
Support in extracting other variables
Besides these basic variables, a researcher might be interested in other information, such as the document type, the age of the victim, sentence length, etc.
To accomplish this, Uwazi allows users to train a machine learning model: the user opens a few documents and manually adds the desired information. This provides example data from which the algorithm learns how to identify the new variable. Once enough example data is gathered, the model suggests corresponding values for so far unprocessed documents. The user can accept or reject these suggestions, and by this provide further feedback to improve the model.
The more examples the algorithm is provided with, the better its suggestions will be. Once the algorithm is good enough, the user can even accept suggestions for an entire group of documents at once.
Quick insights into a document’s content
Documents – especially legal documents – can be very long, making it difficult to identify their main theme. In our vision of Uwazi, users get quick insights into a document’s content by automatically identifying and displaying keywords.
The keywords are in relation to the entire collection: in a human rights document collection the phrase human right will be frequent in many documents so this phrase does not help to identify similar or diverging contents. Uwazi will pull out more meaningful words such as discrimination or women’s rights by giving more weight to the words that are frequent in a document but not too frequent in the entire collection.
These keywords to give user quick and meaningful insights into a document’s content. This feature can be a real time-saver, especially when users have to assess the relevancy of a document for a specific purpose.
New perspectives on data through topic modelling
When too focused on a specific issue, users may risk missing other interesting patterns in the data. With topic modelling, Uwazi can offer new perspectives on the collection of documents.
Using this feature, the algorithm groups words that often appear in similar contexts into ‘topics’. By doing so, patterns that are impossible for a human reader to identify can emerge. For each document the topics and their corresponding relevance are listed.
Furthermore, with topic modelling the similarity of documents can be computed such that when working on certain investigation further documents that deal with similar documents can be suggested. It will also be possible to filter the document collection based on topics.
Over time, these features will become more and more precise as more data is added. Elements such as topics and keyword suggestions are living content, constantly evolving with the document collection.
Join the discussion in the Collaboratory
We’re currently working with several partner organisations to build these machine learning features into Uwazi, but we know we can learn from the experiences and knowledge of others in our community, and share our own experiences with you! We invite you to join the discussion on machine learning in our HURIDOCS Collaboratory! This is a space for human rights practitioners to share their ideas for how this technology could be applied to their work, for machine learning specialists to discuss ways to implement these ideas, and for developers to discuss how to integrate machine learning into existing platforms. Please join us!
If what we’ve described here would be helpful to your work, please contact us! We are actively looking for support to make this vision a reality.
For more information on the Uwazi platform, go to www.uwazi.io, or sign up to our email mailing list here.
This post was written with contributions from Kristin Antin and Daniel Cullen.
We’re able to explore these possibilities with support from the Prototype Fund, a project of the Open Knowledge Foundation Germany and the Federal Ministry of Education and Research.