
Human rights organisations often manage large volumes of essential data, much of it stored in PDFs or other formats that are difficult to search and analyse. To address this challenge, HURIDOCS has integrated machine learning (ML) into Uwazi, our open-source platform. These features help defenders organise, analyse, and access information more efficiently, saving time and reducing the burden of manual tasks.
By making data easier to work with, human rights defenders can focus their efforts on strategic litigation, advocacy, and documenting violations, strengthening their work to promote justice and accountability.
How We Make Change
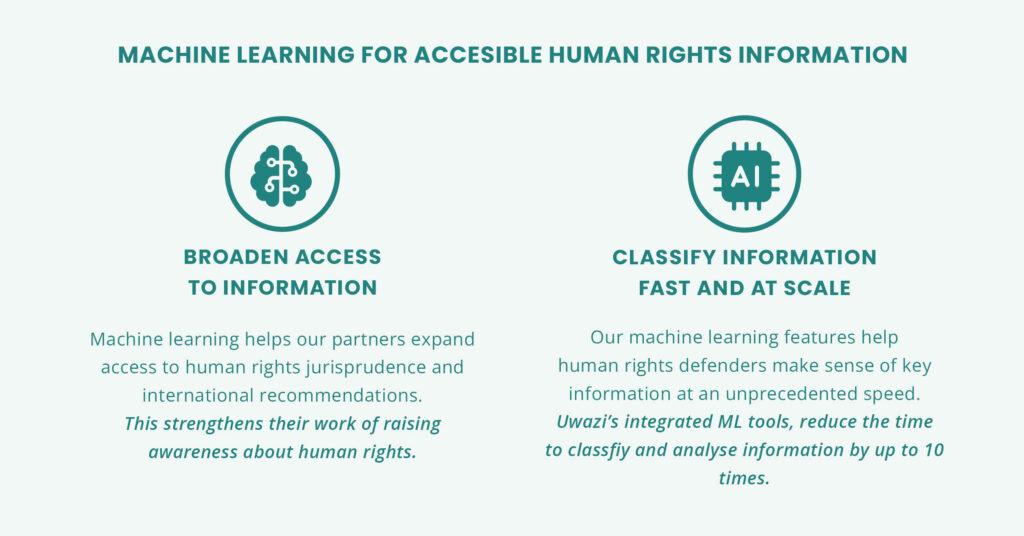
Broadening access to information
Machine learning helps our partners expand access to human rights jurisprudence and international recommendations. This strengthens their work of raising awareness about human rights.
Fast and scalable information classification
Our ML features help human rights defenders make sense of key information at an unprecedented speed. Uwazi’s integrated ML tools reduce the time to classify and analyse information by up to 10 times.
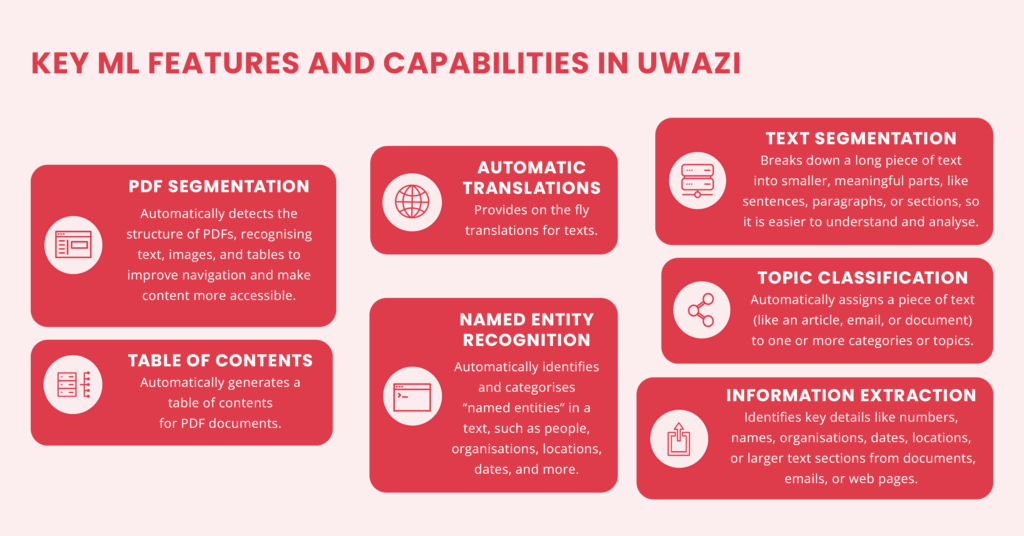
Key ML features in Uwazi
Case studies
CYRILLA: Improving access to digital rights information

CYRILLA is an online portal for legal data related to digital rights around the world. Previously, manually assigning metadata to a single document could take up to three hours. To ease this process, HURIDOCS developed the topic classification feature, which suggests relevant labels for documents based on user input.
The system learns over time, increasing the accuracy of its recommendations and opening the door to future features that can extract and classify new types of information.
“Our partnership with HURIDOCS strengthens CYRILLA with a powerful metadata extraction tool that improves document processing, reduces errors, and ensures continuous learning. This partnership reinforces CYRILLA as a robust, actionable legal resource worldwide.”
— Ibrahim Sabra, Project Coordinator, CYRILLA
SOS-Defenders: Documenting arbitrary detention of human rights defenders
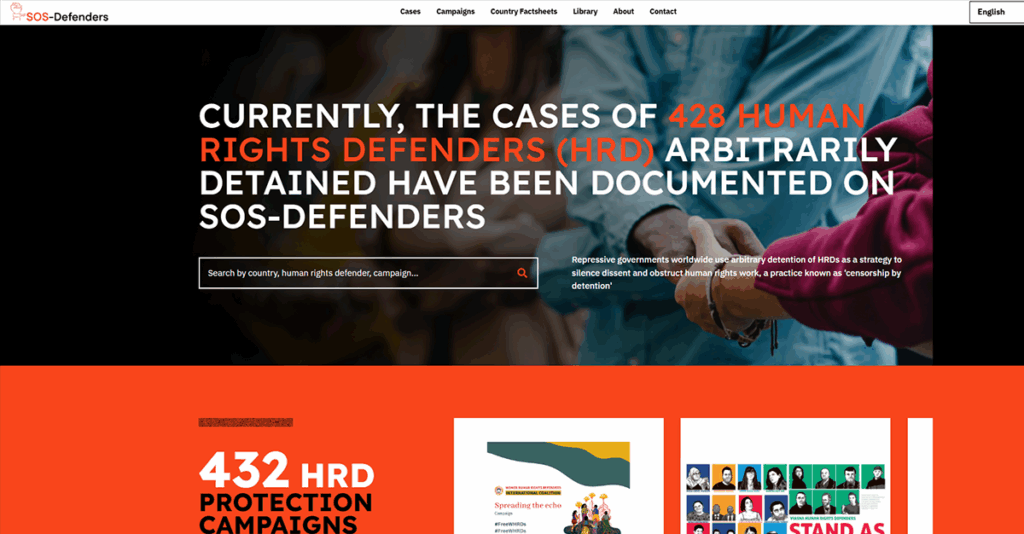
In collaboration with the World Organisation Against Torture (OMCT) and the SOS-Defenders collective, HURIDOCS developed a multilingual Uwazi database to document arbitrary detentions of human rights defenders. The collective includes users and partners in 15 countries.
Machine learning helps the system detect the language of a text and translate it into multiple other active languages. During the pilot phase, 800 records—covering detention cases and liberation campaigns from 23 countries—were automatically translated into Arabic, English, French, Russian, and Spanish. The feature now supports over 20 languages and continues to expand.
“The platform is more accessible for both civil society organisations, who will not need to translate the information collected before uploading it, and users, who will be able to browse the information in any language supported by SOS-Defenders. This while also reducing workload for the platform administrator.”
— Giuseppe Scirocco, Human Rights Analyst, OMCT
UPR Info: Curating and analysing UPR recommendations and pledges
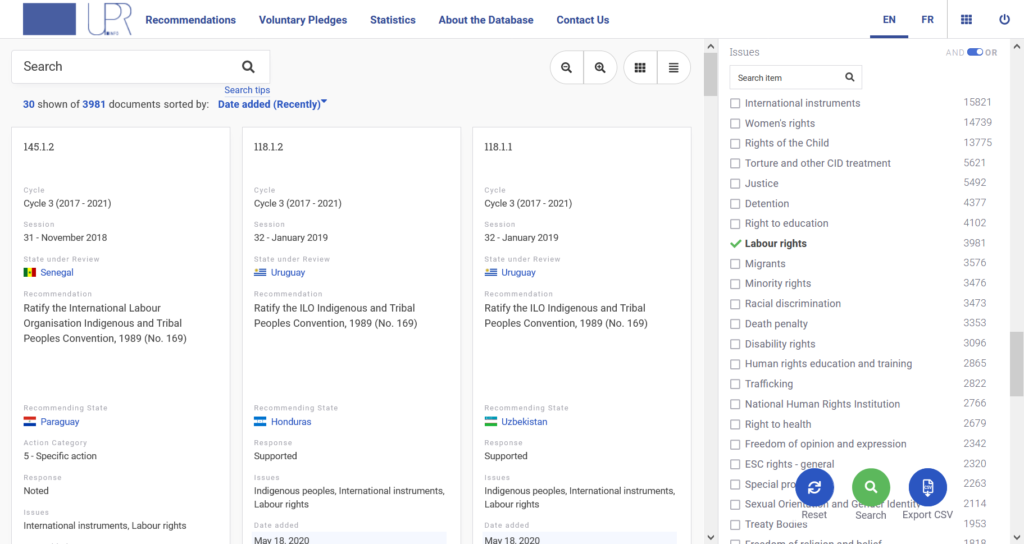
Monitoring the commitments and recommendations from states during the Universal Periodic Review is an essential but resource-heavy task. With a high volume of documentation, curating and analysing data manually takes time.
In partnership with UPR Info, HURIDOCS introduced ML features to an existing database of UPR recommendations and pledges. These updates allow users to categorise recommendations by topic and action type more efficiently, improving accessibility and analysis.
“Updating the database after each cycle has taken from two to three months, to taking one week.“
— Grace Kwak Danciu, Google.org Fellow and Chair, HURIDOCS
Are you ready to take the next steps on your human rights documentation project?
Let’s craft a solution together. Get in touch with us.