
In today’s digital age, PDFs are very common, serving as the go-to format for everything from academic papers and business reports to legal documents and technical manuals. However, extracting and organising information from these documents is a difficult task due to their varied and complex formats.
Recognising these challenges, we decided to develop an advanced open-source PDF Document Layout Analysis Service that leverages state-of-the-art machine learning techniques to provide a robust solution.
Document layout analysis is the process of identifying and understanding the visual structure of a document, such as recognising text, images and tables to extract and organise information automatically.
Our service offers two modes of document layout analysis for PDFs:
- A high-precision visual model for detailed analysis
- A faster non-visual model for quick results
Whether you need high accuracy or speed, our service ensures that you can efficiently extract and organise content from any PDF.
Our service can already be employed on a stand-alone basis (check out the API instructions at the end), but will also become available as a service inside Uwazi, our open-source database application developed for human rights defenders to manage their data collections.
In this article, we’ll delve into the details of our service, explore its features, and guide you through getting started with the API.

Use cases
Since the 1980s, the team at HURIDOCS have been developing documentation technology and strategies for human rights organisations to better manage, share and analyse data. In recent years, we have started to employ machine learning services in our open-source tool Uwazi to help human rights defenders with the curation and management of large information collections.
Our latest machine learning service will enable our users to categorise data more efficiently and with increased speed, precision and accuracy. The service can be used by organisations who need to extract relevant information from huge volumes of PDF documents for classification, analysis, or deriving insights.
The PDF Document Layout Analysis Service is a foundational step for several of our machine learning workflows, including PDF table of contents extraction, PDF text extraction, and PDF metadata extraction.
Apart from our human rights partners who have to sift through thousands of PDF documents to categorise and extract crucial information, other use cases that will benefit from the PDF Document Layout Analysis Service include:
- Academic research:
Extract and organise text, figures, tables and references from research papers to facilitate literature reviews and data analysis. - Legal document analysis:
Analyse and structure legal documents, contracts and case files. - Business reports:
Automate the extraction of financial data, charts, and key metrics from business reports, making it easier to generate insights and summaries. - Archival and digitisation:
Digitise and categorise historical documents, manuscripts, and archives, preserving them in an easily searchable format. - Publishing and media:
Organise and format content from manuscripts, articles, and reports for publishing, ensuring consistency and quality. - Government and compliance:
Extract and organise data from regulatory filings, compliance documents, and public records to enhance transparency and accountability. - Healthcare:
Process medical records, research articles, and clinical trial data to support medical research and patient care. - Education:
Extract and categorise educational content from textbooks, research papers, and course materials to create structured resources for students and educators.
By addressing these diverse use cases, our service demonstrates its versatility and capability to meet the demands of various industries and applications.
“This tool is one of the best tools for analysing PDF layouts that I’ve ever used. It contains simple visualisations and the layout model is perfect in most of the cases I’ve tested.”
– Pavel Karpov, Data Scientist
The problem with content extraction from PDFs
PDFs can contain a wide variety of content types, including text, images, tables, footnotes, and more. These elements are often found scattered in complex layouts that can vary significantly from one document to another. Extracting and categorising these different elements accurately is a time-consuming and difficult task.
Unlike other document formats, PDFs do not inherently contain structured information about the content they display. This means that the logical order of elements (for instance, the flow of text or the placement of images) is not explicitly encoded, making it difficult to reconstruct the original document structure programmatically.
While PDFs can contain tags and metadata that describe the structure and content, these are often inconsistently used or entirely absent in many documents. This lack of standardisation means that relying on metadata alone is insufficient for accurate content extraction.
Given these challenges, rule-based systems for PDF content extraction often fall short. Basic text extraction tools might miss out on crucial contextual information, misinterpret the order of elements, or fail to recognise non-textual components altogether. There is a clear need for more advanced solutions that can handle the diverse and complex nature of PDFs while providing accurate and reliable results.

Our solution: PDF Document Layout Analysis Service
To tackle these challenges of PDF content extraction, we developed the PDF Document Layout Analysis Service, a robust and flexible solution designed to accurately segment and classify various elements within a PDF document. Our service leverages cutting-edge machine learning techniques to provide high-quality results, regardless of the document’s complexity. Here’s a closer look at what our service offers:
Service Overview
Our service features two distinct modes of operation to meet different needs. By offering these two models, our service ensures that users have the flexibility to choose the best option that fits their requirements for the task at hand. Whether you require precise accuracy or need to process large amounts of documents quickly, our service adapts to your requirements, providing an efficient and versatile solution for PDF content extraction and organisation.
This overview highlights the key differences between the two approaches:
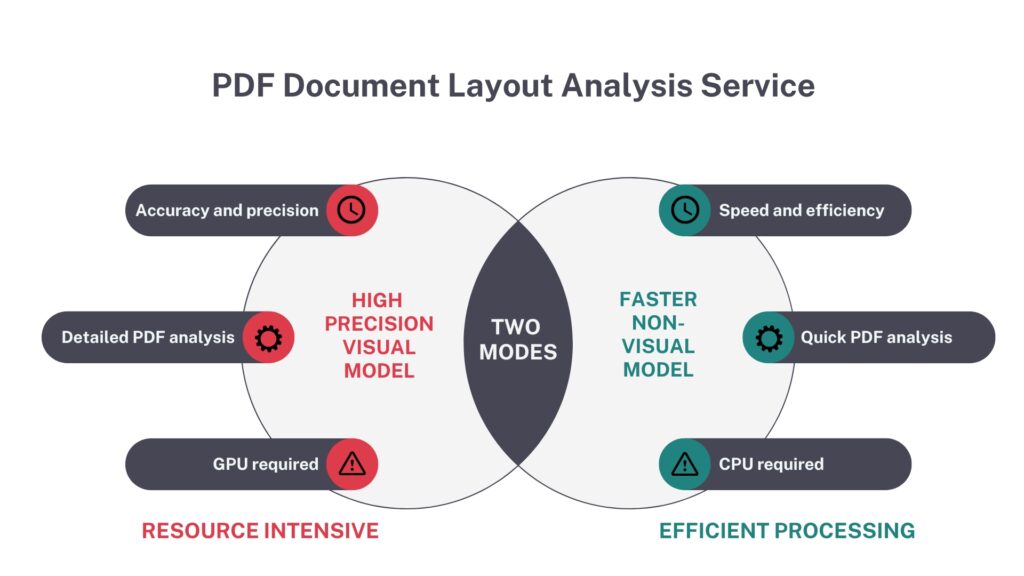
High-precision visual model
The default model is a visual model, specifically called Vision Grid Transformer (VGT), which has been trained by Alibaba Research Group. If you would like to take a look at their original project, you can visit this link. There are various models published by them and according to our benchmarks, the best-performing model is the one trained with the DocLayNet dataset. So, this model is the default model in our project, and it uses more resources than the other model which we ourselves trained. This mode is ideal for scenarios where accuracy is more important.
- Purpose:
This model is designed for scenarios where accuracy is crucial. It leverages visual analysis techniques to precisely segment and classify various elements within a PDF, ensuring high-quality results. - Ideal for:
Use cases such as academic research, detailed document analysis, and other applications where precision and detail are critical. - Resource requirements:
This model is resource-intensive and benefits significantly from GPU support, enabling faster processing and handling of complex documents.
Faster non-visual model
This mode provides faster, non-visual models that perform quick analysis with slightly reduced accuracy. It is suitable for applications where speed and efficiency are prioritised. It will only require your CPU power.
- Purpose:
This model is optimised for speed and efficiency, providing quick analysis with slightly reduced accuracy. It relies on non-visual techniques to deliver faster results. - Ideal for:
Applications where speed and cost-effectiveness are prioritised, such as large-scale document processing, real-time analysis, and scenarios where quick insights are needed. - Resource requirements:
This model requires less computational resources, making it suitable for environments without GPU support or where processing efficiency is a primary concern.
Benchmark
This benchmark evaluation aims to compare the speed and accuracy of the models.
Resources
- Minimum of 2 GB RAM memory.
- (Optional) Minimum of 5 GB GPU memory.
Speed
For a 15-page academic paper document, the following speeds have been recorded:
| Model | GPU | Speed (seconds per page) |
| Fast Model | ✗ [i7-8700 3.2GHz] | 0.42 |
| VGT | ✓ [GTX 1070] | 1.75 |
| VGT | ✗ [i7-8700 3.2GHz] | 13.5 |
Note: These numbers are only included to give you some insight and they can be very different according to your system’s specifications.
Performance
These are the official benchmark results for the VGT model on PubLayNet dataset:
| Overall | Text | Title | List | Table | Figure |
| 0.962 | 0.95 | 0.939 | 0.968 | 0.981 | 0.971 |
You can also check this link to see the comparison with the other models.
Service output
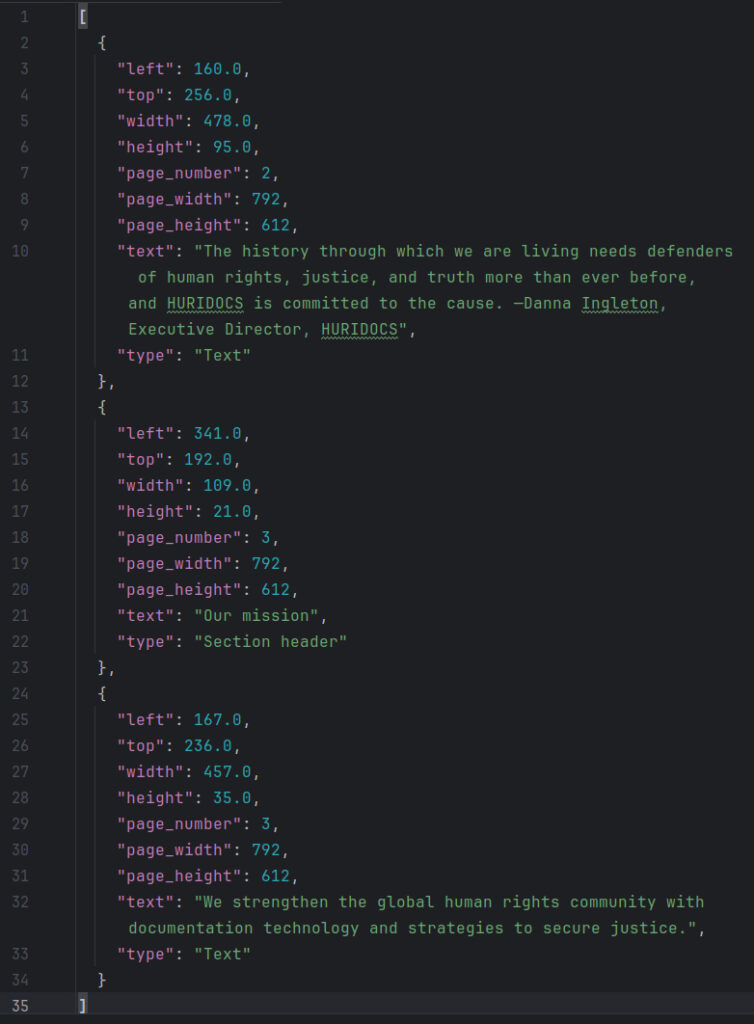
The service takes a PDF as input and produces a structured representation of the document’s content, detailing each segment’s position and type.
Given that the models were trained on the DocLayNet dataset, the supported segment types include:
1: “Caption”
2: “Footnote”
3: “Formula”
4: “List item”
5: “Page footer”
6: “Page header”
7: “Picture”
8: “Section header”
9: “Table”
10: “Text”
11: “Title”
For more information about the data, you can visit this link.
Order of output elements
After processing, the service returns a list of segments in a specific order. This order is primarily determined using Poppler, with additional consideration given to the types of each segment
During the PDF to XML conversion, Poppler determines an initial reading order for each token it creates. These tokens are typically lines of text, but it depends on Poppler’s heuristics. When we extract a segment, it usually consists of multiple tokens. Therefore, for each segment on the page, we calculate an “average reading order” by averaging the reading orders of the tokens within that segment. We then sort the segments based on this average reading order. However, this process is not solely dependent on Poppler, we also consider the types of segments.
- First, we select the “header” segments, sort them among themselves, and place them at the beginning.
- Then, we sort the remaining segments among themselves, excluding “footers” and “footnotes” and place them next to “header” segments.
- As the last step, we sort “footers” and “footnotes” among themselves and place them at the end of the output.
Occasionally, we encounter segments like pictures that might not contain text. Since Poppler cannot assign a reading order to these non-text segments, we process them after sorting all segments with content. To determine their reading order, we rely on the reading order of the nearest “non-empty” segment, using distance as a criterion.

How to use the PDF Document Layout Analysis Service
This open-source service is available on GitHub. Please refer to the README file for detailed documentation. To run the service with default settings, follow these steps:
git clone https://github.com/huridocs/pdf-document-layout-analysis.git
cd pdf-document-layout-analysis
make start
curl -X POST -F ‘file=@/PATH/TO/PDF/pdf_name.pdf’ localhost:5060
make stop
Conclusion
The PDF Document Layout Analysis Service offers a robust solution to the complex challenge of extracting and organising information from PDF documents. By combining cutting-edge machine learning techniques with two distinct operational modes, our service caters to our user base working on human rights documentation as well as a wide range of use cases across various industries. From academic research and legal analysis to business intelligence and archival management.
We invite developers and researchers to contribute to this open-source project. We welcome contributions in the form of code, documentation, or feedback. To get involved, please reach out to the authors or directly engage with the project on GitHub or Hugging Face.
HURIDOCS is a Geneva-based NGO that builds documentation technology and develops strategies that support the global human rights community with securing justice. Since 2016, our team has been working to bring machine learning into Uwazi, our flagship tool for building databases of human rights information. As part of this work, our machine learning specialists have been working on a range of open-source AI models to build upon and include as features inside Uwazi.
This article on our PDF Document Layout Analysis Service is the first in a series to highlight HURIDOCS’ machine learning work. Be sure to check out our upcoming articles on the PDF Table of Contents Extractor and the PDF Text Extraction. These machine learning services will be piloted into Uwazi and we will share information on when they will be available as features for all users of Uwazi.
HURIDOCS gratefully acknowledges Google.org and the Patrick J. McGovern Foundation for supporting our machine learning work.