| What is this? | Who is this for? | How was it created? |
| This resource is intended to help you determine the key questions you want your database to answer, based on your goals and user needs [Read more] | This resource is for human rights defenders who are documenting violations in their communities. [Read more] | This resource was created by human rights defenders. Anyone can suggest changes. Ideas that need some expansion are flagged with a sprout.🌱 [Read more] |
Video summary of this resource #
How to use this resource #
If you already know what a database is, and it is clear what your goals and database queries are (you will need to have a clear understanding of these issues to move forward with this resource), then you are now at the stage of designing the conceptual data model and determining your controlled lists of terms. In the context of the database development timeline, this is where you are at:
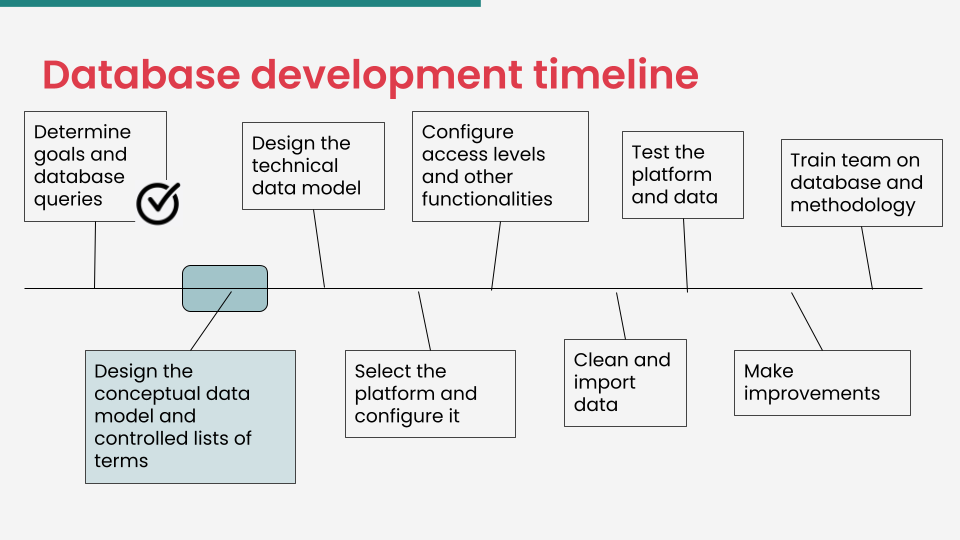
If you are at the stage of figuring out what this is about, then the first section of this resource is for you. There, we explain what a conceptual data model is, why it is important to use it, and we map out its main components: entities, relationships, and attributes.
If you already have some kind of system or have been thinking of a data model to organise your data, but it is still too messy, or you struggle to capture interactions between elements, or you are not able to make sense of real-life relationships in a clear and systematic way, then you might want to further explore the second section of the resource. There we offer key steps, tips and exercises for you to improve on this!
In the third section, you will find some notes on challenges and advice you may want to be aware of. We share the experience of the Berkeley Copwatch to show how they have addressed challenging situations related to their data model. We also provide a short activity that we hope will add value to your process of designing a conceptual data model.
Our intention in creating this resource is to introduce you to a way of thinking about how to organise your information. We have designed this for human rights practitioners who do not necessarily have experience in information management. We know this might seem complicated at first, but once you understand and go through the basics, you will see all the benefits of committing to this process!
What is a conceptual data model and why is it important? #
A conceptual data model (also known as ‘conceptual schema’) is a high-level description of informational needs underlying the design of a database. It represents the main concepts in your database and the relationships between them. It is often represented in a graphical format like a flowchart or a diagram.
Determining an appropriate conceptual data model for your information is important. When done well, the conceptual data model will enable you to answer your database queries (the questions you want your information to answer) and overcome some of the challenges that can arise from using a spreadsheet for information management, as discussed in the previous article on What is a database and do I need one?
The process of conceptualising a data model allows us to translate real world relationships into a framework for understanding our data.
Remember, you do not need to know how your database software will connect all of this information (this is what a technical data model is for). For now, we just want to map out what we think needs to be captured and how it is related to other entities conceptually.
To make this idea more concrete, we will start by giving you an example which illustrates the basic components of a data model, and then we will share the steps you can follow to design your own.
General structure of a conceptual data model #
We’ll start with an example. Let’s say an organisation wants to answer this question: how many prisoners are illegally detained in each prison in country x?
To answer this, an appropriate conceptual data model will include at least two entities (‘Prisoner’ and ‘Prison’, for example) that are connected by a relationship. Determining the number of prisoners detained in each prison necessitates a relationship, or ‘a bridge’, between these two entities (‘Prisoner’ and ‘Prison’) that allows access to the information on each entity. Branching from each entity are the different attributes which describe the respective entities.
One possible conceptual data model for this example could look like this:
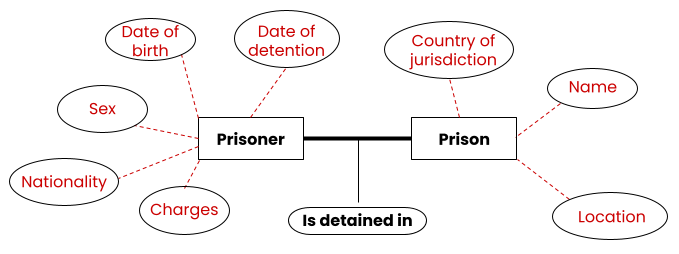
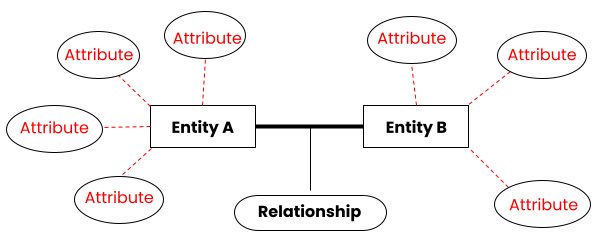
If we wanted to put this in a purely abstract way, the same diagram would look like this:
Essential components of a conceptual data model #
Designing the conceptual data model requires an understanding of the types of components you are going to describe, and how they are related to each other.
As you could see in the diagrams above, there are three basic components in any data model:
- Entities: The real-life things such as people, objects, events, etc. that the database contains information about. (e.g. ‘Officers’, ‘Incidents’, ‘Videos’, ‘Prisoners’, ‘Prisons’). An entity type describes the type of the information that is being recorded (‘Person’, ‘Prison’, ‘Event’, etc.).
- Relationships: How different entities are associated with each other. This can be real-life relationships between different things in your data model. It is often expressed using the formula noun-verb-noun (e.g. prisoner detained at prison).
- Attributes: Aspects of the entities and/or relationships. Attributes will be displayed as fields on each entity in a database (e.g. for an ‘Officer’ entity, attributes could include: ‘First name’, ‘Last name’, ‘Gender’, ‘Location’, ‘Shield number’).
A step-by-step process for designing your conceptual data model #
Step 1: Identify your entities (or entity types) #
As indicated in the previous section, an entity is a single unique object in the real world that is being recorded. By unique we mean that, to be an entity, this object needs to be distinguishable from others (a specific person, a specific place, etc.)
To begin brainstorming on the entities for your conceptual data model, refer back to the questions you want your data to answer (your database queries). Ask yourself: What are the real-life things (people, objects, institutions, incidents) that we are asking questions about?
For example, the organisation that wants to know the number of prisoners illegally detained in each prison will have at the very least the entities ‘Prison’ and ‘Prisoner’. The starting point for identifying these entities might be obtained from a ‘Prisoner Form’ that is filled out on paper or on a device by someone collecting this information:
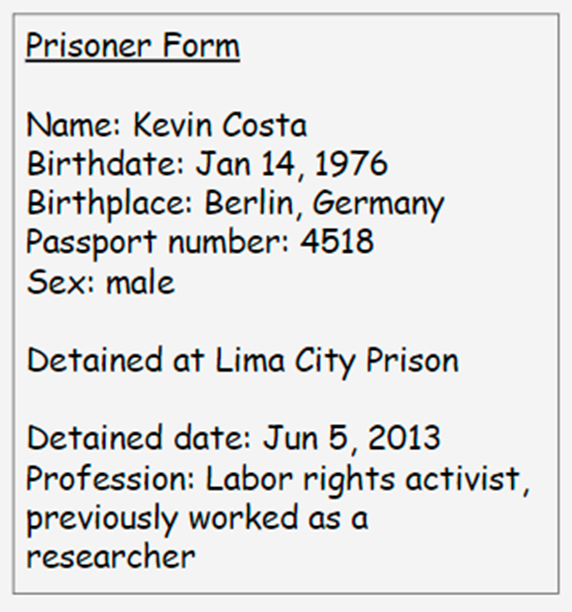
Looking at this information, we ask ourselves, what are the real-life things (people, objects, institutions, incidents) that we are asking questions about? There are two entity types that stand out in this information:
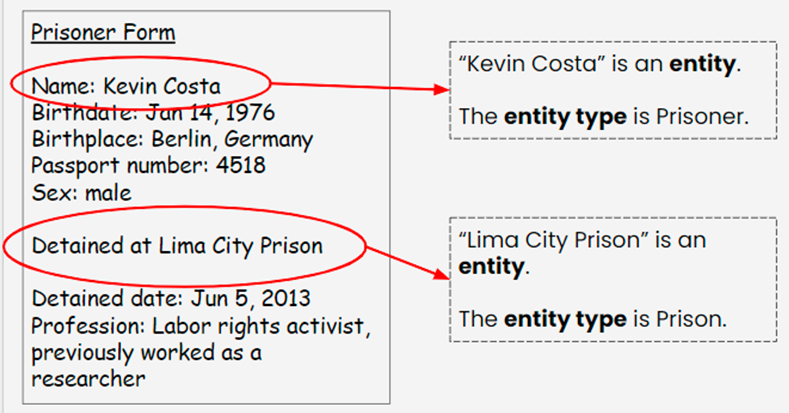
✍🏾 Now you can try to identify your entities and entity types. Use Exercise 1 in this worksheet to write down a list of the real-life things (people, objects, institutions, incidents), and then group them into broader entities that have similar attributes/properties. You may need to draft a few different conceptual data models before you determine the best approach for your information. [We are working on a resource that will offer multiple data models using the same information – stay tuned!]
Step 2: Identify relationships between entities #
The next step is to draw the relationships that we want to examine between your entity types. In the context of this resource, the term relationship means a state of connectedness or an association between two things in a database (Harpring and Baca, 2010).
The relationships will define how entities interact. For example, one act can have various victims, and one perpetrator can be involved in various acts, etc.
Following our previous example, the relationship that connects the entities ‘Kevin Costa’ (the prisoner) and ‘Lima City Prison’ (the prison) would be ‘Is detained at’:
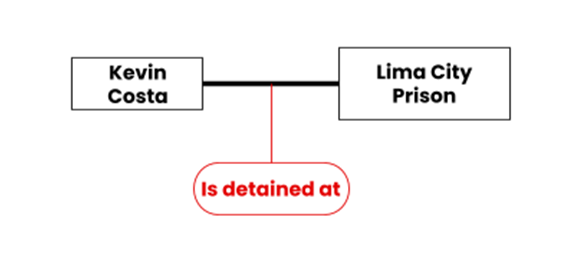
To start brainstorming about the relationships between your entities, you will again refer back to your database queries, and ask yourself: What relationships between entities need to be captured in our database in order to answer these queries?
There are many possible relationships you could imagine, but focus on creating ones that:
- Reflect real-life relationships.
- Are as simple as possible, while being able to answer your research questions.
- Use the sentence formula: entity(noun) — verb — entity(noun)
Examples of relationships in a conceptual data model related to human rights violations:
- A prisoner — is detained in — prison
- A victim — was involved in — an act/incident
- A perpetrator — was involved in — an act/incident
- A video — is a depiction of — an act/incident
- Incident — related secondary source — news article
- A person — is a member of — a group (e.g. an armed group)
- Act of violation — related legislation — document
- Act of violation — related statement — UN recommendation
- An armed group — is present in — a state
- A firm — exploited — workers
- A case — is related to — a case
✍🏾 Use Exercise 2 in this worksheet to work through your ideas for relationships.
Step 3: Identify attributes for entities #
Attributes describe an entity (and sometimes a relationship, but we shall delve deeper into that in another resource). Technically speaking, an attribute identifies, names and defines a characteristic or property of an entity, and determines the fields of a database. But we’ll start simple by just naming what attributes we think we want to capture for each entity.
To identify your attributes, go back to your list of entities. Ask yourself: What are the characteristics of each entity that you must know about your entities in order to answer your database queries? For example, an entity called ‘Prisoner’ might include: ‘Name’, ‘Race’, ‘Gender’, ‘Immigration status’, ‘Health status’, etc.
The organisation interested in understanding the number of prisoners illegally detained in each prison in country X, must determine the attributes of the entities ‘Prison’ and ‘Prisoner’. For example:
- A ‘Prisoner’ (Kevin Costa, in our example) has important attributes including ‘Name’, ‘Date of birth’, ‘Sex’, ‘Date detained’ and ‘Charges’.
- A ‘Prison’ (‘Lima City Prison’) similarly has important attributes such as ‘Name’, ‘Location’, and ‘Country of jurisdiction’.
We can see the attributes that belong with the ‘Prisoner’ entity:
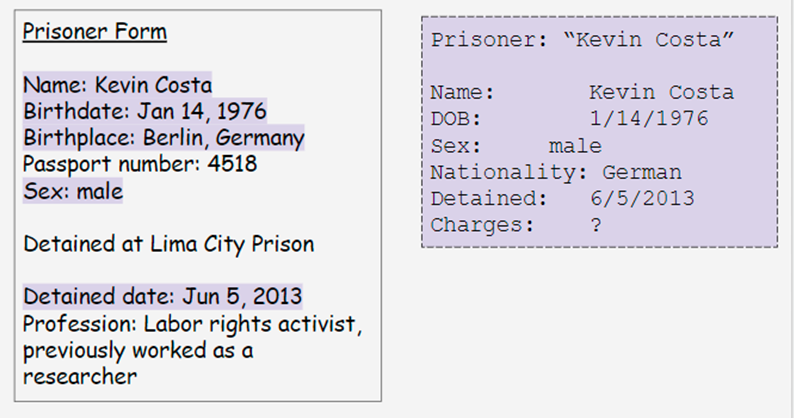
It is clear that there is some information missing from the ‘Prisoner Form’ and that is the charges. So this is something that will need to be investigated further.
When we look at the attributes for the ‘Prison’ entity type and we see that the ‘Prisoner Form’ doesn’t provide a lot of information, but with some research we can determine the values:

Determine what NOT to include in your database #
It may be tempting to want to collect and keep everything you can about a person and/or an event. When making decisions on how to manage your information, it’s important to be intentional about what you include or exclude in your database.
Ask yourself: to what extent is an attribute really needed in connection with your work and goals. Do you really need to collect a person’s ‘Place of birth’, ‘Mother’s name’, ‘Father’s name’, ‘Sexuality’, ‘Passport number’, ‘Immigration status’, etc.? This deeply personal information is potentially dangerous if it falls into the wrong hands.
You can read more about the dangers of collecting personal identifiable information and how to be a responsible steward of this data in the Responsible Data Handbook: Designing a Responsible Data Project.
🌱 [We will be creating resources related to these concerns. If you know of any existing resources, please let us know!]
🌱 Tips for identifying attributes #
- Any entity can have an infinite number of attributes. Choose ones that are important for identifying entities and answering questions. See Determining your controlled lists of terms for more guidance.
- If there’s an important attribute that doesn’t belong to any of the entities already identified, consider making a new entity. Don’t force attributes into an entity it doesn’t describe.
- Consider what data you can realistically collect. Be realistic in terms of the amount of effort and resources it will take to collect the data for these attributes, and the availability of the data (where is the data available? how often is it updated?). It is good to consider the workflow from the very beginning.
- Avoid static numbers that should be dynamic. This includes numbers that will change depending on when you access the information. For instance, register ‘Birth date’ rather than ‘Age’, or ‘Date of detention’ rather than ‘Time spent in prison’.
- One common question about entities is: How do you know whether something is an entity versus an attribute? This is a very good question and may not always have a straightforward answer. Usually, you will want to make something an entity when you know it is an important unit of analysis in your database and it will have attributes of its own. For example, in our hypothetical example of the organisation that wants to know the number of prisoners illegally detained in each prison, we show you the prison as an entity, but one could imagine a prison being an attribute. If all you need to know about the prison is its name, then maybe an attribute is a better way to go to keep it simple. But, if you want the prison to also have a geolocation, a district name, or any other information attached to it, it’s best to make it an entity.
✍🏾 Now it’s your turn to put this into practice! Use Exercise 3 in this worksheet to brainstorm your attributes.
🙌 Use this Connect the Dots group activity to design your conceptual data model together, and make sure everyone understands the common structure that is being developed.
Challenges and advice: Learning from Berkeley Copwatch #
Berkeley Copwatch went through the process of designing their conceptual data model to build the People’s Database for Community-Based Police Accountability. In this section, we will delve into their process and identify some areas where things might get a little more complex or challenging when designing a conceptual data model.
Note: there are many different ways to model or represent real-life things and relationships. Each group needs to make choices about how they will do this, and this example from Berkeley Copwatch illustrates how one organisation chooses to represent the information they collect.
First, Berkeley Copwatch identified their entities by examining what research questions they had for their database. They started with breaking down the question by asking themselves ‘what do I need to know to answer this question?’
For question 1: Do officers conduct searches based on people’s race?, they need to know:
- Information about the officer.
- Information about searches.
- Information about the affected person, including their race.
- That the person was searched.
- How many times a person of one race was searched vs people of other races.
They listed the main THINGS on the left and then determined the ENTITIES that can represent the ‘things’ on the right.
| THINGS – What are the real-life things that these questions are about? | ENTITIES – Can the things above be generalised into a broader entity? | |
| Officers | → | Officer |
| Times/records of searches conducted | → | Incident |
| People who are searched | → | Affected person |
So they ended up with these three entities to start:

Then the Berkeley Copwatch team used the Connect the Dots activity to identify relationships between entities. The project team wrote down the different entities on pieces of paper, taped them up on a wall and used string to connect them where they saw relationships.
To answer the research question: Do officers conduct searches based on people’s race?, the group determined that they needed to capture the following relationships:
- ‘Incident’ involves ‘Officer’ (and conversely, ‘Officer’ is involved in ‘Incident’)
- ‘Incident’ involves ‘Person’ (and conversely, ‘Person’ is involved in ‘Incident’)
Which can be illustrated like this:

You may be asking yourself ‘Why not combine ‘Officer’ and ‘Affected person’ into one entity type called ‘Person’?’ We address this question below.
Next, they identified the attributes for each entity to ensure that they had the appropriate information to answer their research questions.
Berkeley Copwatch wanted to capture attributes for the entities that would help answer the question: ‘Do officers conduct searches based on people’s race?’. Therefore, they wanted to be sure to capture ‘Incident type’ on the ‘Incident’ entity, and ‘Race’ on the ‘Person’ entity, as seen in the diagram below.
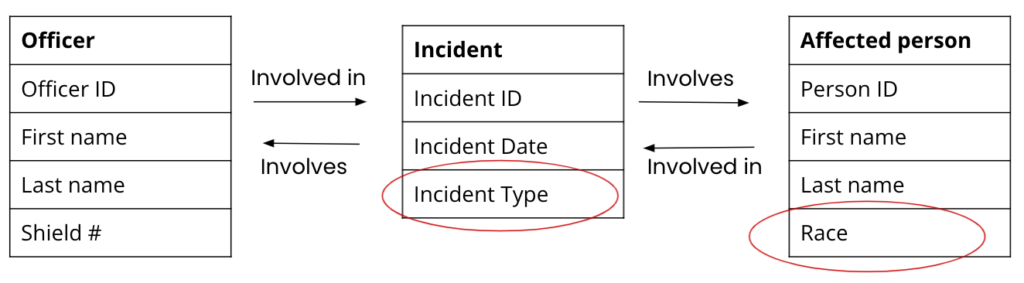
It is important to note that different contexts will have different ways to identify officers. For instance, in countries where there is no rule of law, it is impossible to ask for documentation like an ID for an officer, so maybe you will have other attributes to help you describe and distinguish this person, like ‘Uniform description’.
🤔 One question that can arise when identifying your entities is: How do you know the right level of abstraction?
In this example, Berkeley Copwatch decided to use different entities for ‘Officer’ and ‘Affected person’, instead of using one entity called ‘Person’ and differentiating between an officer and an affected person using attributes. Both of these approaches are valid. Each approach has pros and cons.
Using a more abstract entity type may result in many empty fields on each entity because your attributes will need to cover many more entities in your database. For example, the attributes that are specific to a police officer, like ‘Badge number’, ‘Uniform description’, or ‘Precinct number’, are not applicable to an incident victim or bystander. As such, you will be left with a lot of blank attribute fields.
Conversely, you may find that two entity types have many overlapping attributes so it makes more sense to combine them into one entity type.
One situation that you will want to avoid is any duplication of information in your database. For example, a database may use the entity type ‘Deceased prisoner’ and another entity type called ‘Prisoner’. It is possible that a record in your database registered as ‘Prisoner’ becomes a ‘Deceased prisoner’, which would require a new entity to capture this information – resulting in two entities with the information about the same person. This can lead to many problems with analysis. It is better in situations like these, to be more abstract, and find another way to record whether the prisoner is deceased or not (e.g. using a term list called ‘Status’ and including ‘Deceased’ as one of the options).
[We plan to explore more about this question about the depth of abstraction and how it can affect your conceptual data model in a future resource. If you have specific examples or questions, please get in touch!]🌱
🪴 Help us improve this content by suggesting changes to this content via Google Docs!
References #
- Patricia Harpring. Introduction to Controlled Vocabularies: Terminology for Art, Architecture, and Other Cultural Works. (2010). Last accessed January 27, 2022 from https://www.getty.edu/research/publications/electronic_publications/intro_controlled_vocab/
Further Reading #
Patrick Ball. Who Did What to Whom? Planning and Implementing a Large Scale Human Rights Data Project. (1996) American Association for the Advancement of Science. Last accessed December 11, 2021 at https://hrdag.org/whodidwhattowhom/contents.html
The Engine Room. Responsible Data Handbook: Designing a Responsible Data Project. (2016). Last accessed January 2, 2022 at https://the-engine-room.github.io/responsible-data-handbook/chapters/chapter-01-designing-a-project.html



